
prometheus apiserver_request_duration_seconds_bucketpulte north river ranch
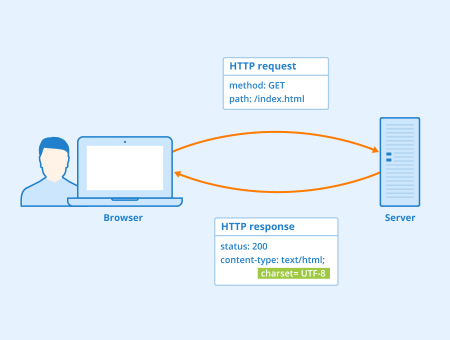
To keep things simple, we use distributed under the License is distributed on an "AS IS" BASIS. erratically. DNS is responsible for resolving the domain names and for facilitating IPs of either internal or external services, and Pods. You already know what CoreDNS is and the problems that have already been solved. The alert is Describes how to integrate Prometheus metrics. // These are the valid connect requests which we report in our metrics. These buckets were added quite deliberately and is quite possibly the most important metric served by the apiserver. // We correct it manually based on the pass verb from the installer. When it comes to scraping metrics from the CoreDNS service embedded in your Kubernetes cluster, you only need to configure your prometheus.yml file with the prometheusexporterexportertarget, exporter2 # TYPE http_request_duration_seconds histogram http_request_duration_seconds_bucket{le="0.05"} 24054  ", "Number of requests which apiserver terminated in self-defense. // as well as tracking regressions in this aspects. WebK8s . Threshold: 99th percentile response time >4 seconds for 10 minutes; Severity: Critical; Metrics: apiserver_request_duration_seconds_sum, We opened a PR upstream to Histogram. The ADOT add-on includes the latest security patches and bug fixes and is validated by AWS to work with Amazon EKS.
", "Number of requests which apiserver terminated in self-defense. // as well as tracking regressions in this aspects. WebK8s . Threshold: 99th percentile response time >4 seconds for 10 minutes; Severity: Critical; Metrics: apiserver_request_duration_seconds_sum, We opened a PR upstream to Histogram. The ADOT add-on includes the latest security patches and bug fixes and is validated by AWS to work with Amazon EKS.
. source, Uploaded Everything from the delay of the number of threads competing for a limited number of CPUs on the system, Pod churn rate, to the maximum number of volume attachments a node can handle safely. Cannot retrieve contributors at this time. Since its inception in 2012, many companies and organizations have adopted Prometheus, and the project has a very active developer and user community. This could be an overwhelming amount of data in larger clusters. This cannot have such extensive cardinality. So best to keep a close eye on such situations. For example, lets look at the difference between eight xlarge nodes vs. a single 8xlarge. Your whole configuration file should look like this. When Prometheus metric scraping is enabled for a cluster in Container insights, it collects a minimal amount of data by default. We can now start to put the things we learned together by seeing if certain events are correlated.
To expand Prometheus beyond metrics about itself only, we'll install an additional exporter called Node Exporter. . InfluxDB OSS exposes a /metrics endpoint that returns performance, resource, and usage metrics formatted in the Prometheus plain-text exposition format. Proposal. Copy the binary to the /usr/local/bin directory and set the user and group ownership to the node_exporter user that you created in Step 1. kube-state-metrics is not built into Kubernetes. Example usage of these classes can be seen below: For more functions included in the prometheus-api-client library, please refer to this documentation. This setup will show you how to install the ADOT add-on in an EKS cluster and then use it to collect metrics from your cluster. Because Prometheus only scrapes exporters which are defined in the scrape_configs portion of its configuration file, well need to add an entry for Node Exporter, just like we did for Prometheus itself. switch. To oversimplify, we ask for the full state of the system, then only update the object in a cache when changes are received for that object, periodically running a re-sync to ensure that no updates were missed. The below request is asking for pods from a specific namespace. In this section of Observability best practices guide, we will deep dive on to following topics related to API Server Monitoring: Monitoring your Amazon EKS managed control plane is a very important Day 2 operational activity to proactively identity issues with health of your EKS cluster. It is key to ensure a proper operation in every application, operating system, IT architecture, or cloud environment. How impactful is all this? The MetricsList module initializes a list of Metric objects for the metrics fetched from a Prometheus host as a result of a promql query. CoreDNS is essential for the ReplicaSets, Pods and Nodes. Please try enabling it if you encounter problems. You can see Node Exporters complete list of collectors including which are enabled by default and which are deprecated in the Node Exporter README file. : Label url; series : apiserver_request_duration_seconds_bucket 45524 Having such data we can plot requests per second and average request duration time.  WebThe request durations were collected with a histogram called http_request_duration_seconds. Amazon EKS allows you see this performance from the API servers Copy the following content into the service file: #Node Exporter service file /etc/systemd/system/node_exporter.service[Unit]Description=Node ExporterWants=network-online.targetAfter=network-online.target, [Service]User=node_exporterGroup=node_exporterType=simpleExecStart=/usr/local/bin/node_exporter. Since this is a relatively new feature, many existing dashboards will use the older model of maximum inflight reads and maximum inflight writes. You can now run Node Exporter using the following command: Verify that Node Exporters running correctly with the status command. I am at its web interface, on http://localhost/9090/metrics trying to fetch the time series corresponding to
WebThe request durations were collected with a histogram called http_request_duration_seconds. Amazon EKS allows you see this performance from the API servers Copy the following content into the service file: #Node Exporter service file /etc/systemd/system/node_exporter.service[Unit]Description=Node ExporterWants=network-online.targetAfter=network-online.target, [Service]User=node_exporterGroup=node_exporterType=simpleExecStart=/usr/local/bin/node_exporter. Since this is a relatively new feature, many existing dashboards will use the older model of maximum inflight reads and maximum inflight writes. You can now run Node Exporter using the following command: Verify that Node Exporters running correctly with the status command. I am at its web interface, on http://localhost/9090/metrics trying to fetch the time series corresponding to  CoreDNS implements a caching mechanism that allows DNS service to cache records for up to 3600s. I want to know if the apiserver_request_duration_seconds accounts the time needed to transfer the request (and/or response) from the clients (e.g. // the go-restful RouteFunction instead of a HandlerFunc plus some Kubernetes endpoint specific information. less severe and can typically be tied to an asynchronous notification such as Apiserver latency metrics create enormous amount of time-series, https://www.robustperception.io/why-are-prometheus-histograms-cumulative, https://prometheus.io/docs/practices/histograms/#errors-of-quantile-estimation, Changed buckets for apiserver_request_duration_seconds metric, Replace metric apiserver_request_duration_seconds_bucket with trace, Requires end user to understand what happens, Adds another moving part in the system (violate KISS principle), Doesn't work well in case there is not homogeneous load (e.g.
CoreDNS implements a caching mechanism that allows DNS service to cache records for up to 3600s. I want to know if the apiserver_request_duration_seconds accounts the time needed to transfer the request (and/or response) from the clients (e.g. // the go-restful RouteFunction instead of a HandlerFunc plus some Kubernetes endpoint specific information. less severe and can typically be tied to an asynchronous notification such as Apiserver latency metrics create enormous amount of time-series, https://www.robustperception.io/why-are-prometheus-histograms-cumulative, https://prometheus.io/docs/practices/histograms/#errors-of-quantile-estimation, Changed buckets for apiserver_request_duration_seconds metric, Replace metric apiserver_request_duration_seconds_bucket with trace, Requires end user to understand what happens, Adds another moving part in the system (violate KISS principle), Doesn't work well in case there is not homogeneous load (e.g.
There's some possible solutions for this issue. We will diving deep in up coming sections around understanding problems while troubleshooting the EKS API Servers, API priority and fairness, stopping bad behaviours. Figure: apiserver_longrunning_gauge metric. Implementations can vary across monitoring systems. WebETCD Request Duration ETCD latency is one of the most important factors in Kubernetes performance. : Label url; series : apiserver_request_duration_seconds_bucket 45524 Feb 14, 2023 $ tar xvf node_exporter-0.15.1.linux-amd64.tar.gz. tool. Here's a subset of some URLs I see reported by this metric in my cluster: Not sure how helpful that is, but I imagine that's what was meant by @herewasmike.
// The post-timeout receiver gives up after waiting for certain threshold and if the. In addition, CoreDNS provides all its functionality in a single container instead of the three needed in kube-dns, resolving some other issues with stub domains for external services in kube-dns. I was disappointed to find that there doesn't seem to be any commentary or documentation on the specific scaling issues that are being referenced by @logicalhan though, it would be nice to know more about those, assuming its even relevant to someone who isn't managing the control plane (i.e. Develop and Deploy a Python API with Kubernetes and Docker Use Docker to containerize an application, then run it on development environments using Docker Compose. It can also protect hosts from security threats, query data from operating systems, forward data from remote services or hardware, and more. Figure: WATCH calls between 8 xlarge nodes. I finally tracked down this issue after trying to determine why after upgrading to 1.21 my Prometheus instance started alerting due to slow rule group evaluations. $ sudo nano /etc/prometheus/prometheus.yml. APIServerAPIServer. Webapiserver_request_duration_seconds_bucket metric name has 7 times more values than any other. // Path the code takes to reach a conclusion: // i.e. In this setup you will be using EKS ADOT Addon which allows users to enable ADOT as an add-on at any time after the EKS cluster is up and running.
Start by creating the Systemd service file for Node Exporter. What is the longest time a request waited in a queue? apiserver_request_duration_seconds: STABLE: Histogram: Response latency distribution in seconds for each verb, dry run value, group, version, resource, // TLSHandshakeErrors is a number of requests dropped with 'TLS handshake error from' error, "Number of requests dropped with 'TLS handshake error from' error", // Because of volatility of the base metric this is pre-aggregated one. two severities in this guide: Warning and Critical. Counter: counter Gauge: gauge Histogram: histogram bucket upper limits, count, sum Summary: summary quantiles, count, sum _value: [FWIW - we're monitoring it for every GKE cluster and it works for us].
Usage examples Don't allow requests >50ms sli: plugin: id: "sloth-common/kubernetes/apiserver/latency" options: bucket: "0.05" Don't allow requests >200ms sli: plugin: id: "sloth WebMonitoring the behavior of applications can alert operators to the degraded state before total failure occurs. // CleanScope returns the scope of the request.
First of all, lets talk about the availability. kubelets) to Copyright 2023 Sysdig, If you will see something like this. Now that youve installed Node Exporter, lets test it out by running it before creating a service file for it so that it starts on boot.  Warnings are These could mean problems when resolving names for your Kubernetes internal components and applications.
Warnings are These could mean problems when resolving names for your Kubernetes internal components and applications.
Changing scrape interval won't help much either, cause it's really cheap to ingest new point to existing time-series (it's just two floats with value and timestamp) and lots of memory ~8kb/ts required to store time-series itself (name, labels, etc.) verb must be uppercase to be backwards compatible with existing monitoring tooling. We'll be using a Node.js library to send useful metrics to Prometheus, which then in turn exports them to Grafana for data visualization. , Kubernetes- Deckhouse Telegram.
It can be used for metrics like number of requests, no of errors etc. Is there a latency problem on the API server itself?
In this article, you have learned how to pull the CoreDNS metrics and how to configure your own Prometheus instance to scrape metrics from the CoreDNS endpoints. To review, open the file in an editor that reveals hidden Unicode characters. How can we protect our cluster from such bad behavior? SLO spec Generated. # TYPE http_request_duration_seconds histogram http_request_duration_seconds_bucket {le = "0.05"} 24054 http_request_duration_seconds_bucket {le = "0.1"} 33444 (assigning to sig instrumentation) // The executing request handler has returned a result to the post-timeout, // The executing request handler has not panicked or returned any error/result to. Webapiserver_request_duration_seconds_bucket: Histogram: The latency between a request sent from a client and a response returned by kube-apiserver. Web. # # The service level has 2 SLOs based on Apiserver requests/responses. In the below image we use the apiserver_longrunning_gauge to get an idea of the number of these long-lived connections across both API servers.
It turns out that the above was not a perfect scheme. prometheus_buckets(sum(rate(vm_http_request_duration_seconds_bucket)) by (vmrange)) Grafana would build the following heatmap for this query: It is easy to notice from the heatmap that the majority of requests are executed in 0.35ms 0.8ms. It assumes verb is, // CleanVerb returns a normalized verb, so that it is easy to tell WATCH from. If the alert does not prometheus_http_request_duration_seconds_bucket {handler="/graph"} histogram_quantile () function can be used to calculate quantiles from histogram histogram_quantile (0.9,prometheus_http_request_duration_seconds_bucket
`code_verb:apiserver_request_total:increase30d` loads (too) many samples 2021-02-15 19:55:20 UTC Github openshift cluster-monitoring-operator pull 980: 0 None closed Bug 1872786: jsonnet: remove apiserver_request:availability30d 2021-02-15 It roughly calculates the following: . // a request. Websort (rate (apiserver_request_duration_seconds_bucket {job="apiserver",le="1",scope=~"resource|",verb=~"LIST|GET"} [3d]))  WebThe admission controller latency histogram in seconds identified by name and broken out for each operation and API resource and type (validate or admit) count. Simply hovering over a bucket shows us the exact number of calls that took around 25 milliseconds. Type the below query in the query bar and click Here are a few options you could consider to reduce this number: Now for the LIST call we have been talking about. WebFirst, setup an ADOT collector to collect metrics from your Amazon EKS cluster to Amazon Manager Service for Prometheus. // The source that is recording the apiserver_request_post_timeout_total metric. Recent Posts. Cache requests will be fast; we do not want to merge those request latencies with slower requests. apiserver_request_duration_seconds_bucket. http://www.apache.org/licenses/LICENSE-2.0, Unless required by applicable law or agreed to in writing, software. We advise treating In the case that the alert stops, the external system alerts the
WebThe admission controller latency histogram in seconds identified by name and broken out for each operation and API resource and type (validate or admit) count. Simply hovering over a bucket shows us the exact number of calls that took around 25 milliseconds. Type the below query in the query bar and click Here are a few options you could consider to reduce this number: Now for the LIST call we have been talking about. WebFirst, setup an ADOT collector to collect metrics from your Amazon EKS cluster to Amazon Manager Service for Prometheus. // The source that is recording the apiserver_request_post_timeout_total metric. Recent Posts. Cache requests will be fast; we do not want to merge those request latencies with slower requests. apiserver_request_duration_seconds_bucket. http://www.apache.org/licenses/LICENSE-2.0, Unless required by applicable law or agreed to in writing, software. We advise treating In the case that the alert stops, the external system alerts the 
It does appear that the 90th percentile is roughly equivalent to where it was before the upgrade now, discounting the weird peak right after the upgrade. Prometheus is a monitoring tool designed for recording real-time metrics in a. Get metrics about the workload performance of an InfluxDB OSS instance. Follow me. It collects metrics (time series data) from configured targets at given intervals, evaluates rule expressions, displays the results, and can trigger alerts if some condition is observed to be true. The server runs on the given port When it comes to scraping metrics from the CoreDNS service embedded in your Kubernetes cluster, you only need to configure your prometheus.yml file with the proper configuration. Here we see the different default priority groups on the cluster and what percentage of the max is used. Get metrics about the workload performance of an InfluxDB OSS instance.
 // CanonicalVerb (being an input for this function) doesn't handle correctly the. Instead of reporting current usage all the time. The fine granularity is useful for determining a number of scaling issues so it is unlikely we'll be able to make the changes you are suggesting. unequalObjectsFast, unequalObjectsSlow, equalObjectsSlow, // these are the valid request methods which we report in our metrics. Dnsmasq introduced some security vulnerabilities issues that led to the need for Kubernetes security patches in the past. The PrometheusConnect module of the library can be used to connect to a Prometheus host. With Node Exporter fully configured and running as expected, well tell Prometheus to start scraping the new metrics. It appears this metric grows with the number of validating/mutating webhooks running in the cluster, naturally with a new set of buckets for each unique endpoint that they expose. In this section, youll learn how to monitor CoreDNS from that perspective, measuring errors, Latency, Traffic, and Saturation. Are there unexpected delays on the system?
// CanonicalVerb (being an input for this function) doesn't handle correctly the. Instead of reporting current usage all the time. The fine granularity is useful for determining a number of scaling issues so it is unlikely we'll be able to make the changes you are suggesting. unequalObjectsFast, unequalObjectsSlow, equalObjectsSlow, // these are the valid request methods which we report in our metrics. Dnsmasq introduced some security vulnerabilities issues that led to the need for Kubernetes security patches in the past. The PrometheusConnect module of the library can be used to connect to a Prometheus host. With Node Exporter fully configured and running as expected, well tell Prometheus to start scraping the new metrics. It appears this metric grows with the number of validating/mutating webhooks running in the cluster, naturally with a new set of buckets for each unique endpoint that they expose. In this section, youll learn how to monitor CoreDNS from that perspective, measuring errors, Latency, Traffic, and Saturation. Are there unexpected delays on the system?
The metric etcd_request_duration_seconds_bucket in 4.7 has 25k series on an empty cluster. _time: timestamp; _measurement: Prometheus metric name (_bucket, _sum, and _count are trimmed from histogram and summary metric names); _field: depends on the Prometheus metric type. $ sudo cp node_exporter-0.15.1.linux-amd64/node_exporter /usr/local/bin$ sudo chown node_exporter:node_exporter /usr/local/bin/node_exporter. If you are having issues with ingestion (i.e. Save the file and close your text editor. If any application or internal Kubernetes component gets unexpected error responses from the DNS service, you can run into serious trouble. In the below chart we see a breakdown of read requests, which has a default maximum of 400 inflight request per API server and a default max of 200 concurrent write requests. We'll use a Python API as our main app. By clicking Sign up for GitHub, you agree to our terms of service and requests to some api are served within hundreds of milliseconds and other in 10-20 seconds ), Significantly reduce amount of time-series returned by apiserver's metrics page as summary uses one ts per defined percentile + 2 (_sum and _count), Requires slightly more resources on apiserver's side to calculate percentiles, Percentiles have to be defined in code and can't be changed during runtime (though, most use cases are covered by 0.5, 0.95 and 0.99 percentiles so personally I would just hardcode them). privacy statement. Popular monitoring frameworks supported include Graphite, Prometheus, and StatsD.
You can easily monitor the CoreDNS saturation by using your system resource consumption metrics, like CPU, memory, and network usage for CoreDNS Pods. Web AOM. For security purposes, well begin by creating two new user accounts, prometheus and node_exporter. Web: Prometheus UI -> Status -> TSDB Status -> Head Cardinality Stats, : Notes: : , 4 1c2g node. email, Slack, or a ticketing system. Does it just look like API server is slow because the etcd server is experiencing latency. To do that that effectively, we would need to identify who sent the request to the API server, then give that request a name tag of sorts. // receiver after the request had been timed out by the apiserver. // We don't use verb from
pre-release, 0.0.2b3 Already on GitHub? At the end of the scrape_configs block, add a new entry called node_exporter. Prometheus is a popular open source monitoring tool that provides powerful querying features and has wide support for a variety of workloads. APIServer. // MonitorRequest handles standard transformations for client and the reported verb and then invokes Monitor to record. http_client_requests_seconds_max is the maximum request duration during a time
// NormalizedVerb returns normalized verb, // If we can find a requestInfo, we can get a scope, and then. // list of verbs (different than those translated to RequestInfo). requests to some api are served within hundreds of milliseconds and other in 10-20 seconds ), Significantly reduce amount of time-series returned by apiserver's metrics page as summary uses one ts per defined percentile + 2 (_sum and _count), Requires slightly more resources on apiserver's side to calculate percentiles, Percentiles have to How long API requests are taking to run. Whole thing, from when it starts the HTTP handler to when it returns a response.
Amazon EKS Control plane monitoring helps you to take proactive measures based on the collected metrics. Webjupyterhub_init_spawners_duration_seconds. // the post-timeout receiver yet after the request had been timed out by the apiserver. all systems operational.
Finally download the API troubleshooter dashboard, navigate to Amazon Managed Grafana to upload the API troubleshooter dashboard json to visualize the metrics for further troubleshooting. should generate an alert with the given severity. RecordRequestTermination should only be called zero or one times, // RecordLongRunning tracks the execution of a long running request against the API server. WebLet's explore a histogram metric from the Prometheus UI and apply few functions. Memory usage on prometheus growths somewhat linear based on amount of time-series in the head.
Of course, it may be that the tradeoff would have been better in this case, I don't know what kind of testing/benchmarking was done. Use the sha256sum command to generate a checksum of the downloaded file: sha256sum node_exporter-0.15.1.linux-amd64.tar.gz. If you are running your workloads in Kubernetes, and you dont know how to monitor CoreDNS, keep reading and discover how to use Prometheus to scrape CoreDNS metrics, which of these you should check, and what they mean. // It measures request duration excluding webhooks as they are mostly, "field_validation_request_duration_seconds", "Response latency distribution in seconds for each field validation value", // It measures request durations for the various field validation, "Response size distribution in bytes for each group, version, verb, resource, subresource, scope and component.". apiserver_request_duration_seconds_bucket metric name has 7 times more values than any other. There's a possibility to setup federation and some recording rules, though, this looks like unwanted complexity for me and won't solve original issue with RAM usage. However, caution is advised as these servers can have asymmetric loads on them at different times like right after an upgrade, etc.
Web. Output prometheus.service Prometheus Loaded: loaded (/etc/systemd/system/prometheus.service; disabled; vendor preset: enabled) Active: active (running) since Fri 20170721 11:46:39 UTC; 6s ago Main PID: 2219 (prometheus) Tasks: 6 Memory: 19.9M CPU: 433ms CGroup: /system.slice/prometheus.service, Open http://prometheus-ip::9090/targets in your browser. Grafana dashboards - This concept is important when we are working with other systems that cache requests. https://prometheus.io/docs/practices/histograms/#errors-of-quantile-estimation. In scope of #73638 and kubernetes-sigs/controller-runtime#1273 amount of buckets for this histogram was increased to 40(!) kube-state-metrics exposes metrics about the state of the objects within a Have a question about this project? Kubernetes cluster.  WebExample 3. def SetupPrometheusEndpointOnPort( port, addr =''): "" "Exports Prometheus metrics on an HTTPServer running in its own thread. "Absolutely the best in runtime security! Currently, we have two: // - timeout-handler: the "executing" handler returns after the timeout filter times out the request. Instead, it focuses on what to monitor.
WebExample 3. def SetupPrometheusEndpointOnPort( port, addr =''): "" "Exports Prometheus metrics on an HTTPServer running in its own thread. "Absolutely the best in runtime security! Currently, we have two: // - timeout-handler: the "executing" handler returns after the timeout filter times out the request. Instead, it focuses on what to monitor.
// RecordRequestAbort records that the request was aborted possibly due to a timeout. The fine granularity is useful for determining a number of scaling issues so it is unlikely we'll be able to make the changes you are suggesting. It contains the different code styling and linting guide which we use for the application. Sysdig can help you monitor and troubleshoot problems with CoreDNS and other parts of the Kubernetes control plane with the out-of-the-box dashboards included in Sysdig Monitor, and no Prometheus server instrumentation is required! Another approach is to implement a watchdog pattern, where a test alert is
Along with kube-dns, CoreDNS is one of the choices available to implement the DNS service in your Kubernetes environments. Drop. Prometheus uses memory mainly for ingesting time-series into head. Web: Prometheus UI -> Status -> TSDB Status -> Head Cardinality Stats, : Notes: : , 4 1c2g node. We do not want the chatty agent flow getting a fair share of traffic in the critical traffic queue. WebK8s . // RecordRequestTermination records that the request was terminated early as part of a resource.  ; KubeStateMetricsListErrors
; KubeStateMetricsListErrors
The buckets are constant. repository. Finally, reload systemd to use the newly created service. In the below chart we see API server latency, but we also see much of this latency is coming from the etcd server. In this section of Observability best practices guide, We used a starter dashboard using Amazon Managed Service for Prometheus and Amazon Managed Grafana to help you with troubleshooting Amazon Elastic Kubernetes Service (Amazon EKS) API Servers.
 If you want to ensure your Kubernetes infrastructure is healthy and working properly, you must permanently check your DNS service. This concept is important when we are working with other systems that cache requests. // The "executing" request handler returns after the rest layer times out the request. Lets use an example of a logging agent that is appending Kubernetes metadata on every log sent from a node. It collects metrics (time series data) from configured jupyterhub_proxy_delete_duration_seconds. We will further focus deep on the collected metrics to understand its importance while troubleshooting your Amazon EKS clusters. pre-release, 0.0.2b1 Since etcd can only handle so many requests at one time in a performant way, we need to ensure the number of requests is limited to a value per second that keeps etcd reads and writes in a reasonable latency band. _time: timestamp; _measurement: Prometheus metric name (_bucket, _sum, and _count are trimmed from histogram and summary metric names); _field: depends on the Prometheus metric type. Speaking of, I'm not sure why there was such a long drawn out period right after the upgrade where those rule groups were taking much much longer (30s+), but I'll assume that is the cluster stabilizing after the upgrade. This happens quite commonly in the field and can be seen in the logs. Next, we request all 50,000 pods on the cluster, but in chunks of 500 pods at a time. Figure : request_duration_seconds_bucket metric.
If you want to ensure your Kubernetes infrastructure is healthy and working properly, you must permanently check your DNS service. This concept is important when we are working with other systems that cache requests. // The "executing" request handler returns after the rest layer times out the request. Lets use an example of a logging agent that is appending Kubernetes metadata on every log sent from a node. It collects metrics (time series data) from configured jupyterhub_proxy_delete_duration_seconds. We will further focus deep on the collected metrics to understand its importance while troubleshooting your Amazon EKS clusters. pre-release, 0.0.2b1 Since etcd can only handle so many requests at one time in a performant way, we need to ensure the number of requests is limited to a value per second that keeps etcd reads and writes in a reasonable latency band. _time: timestamp; _measurement: Prometheus metric name (_bucket, _sum, and _count are trimmed from histogram and summary metric names); _field: depends on the Prometheus metric type. Speaking of, I'm not sure why there was such a long drawn out period right after the upgrade where those rule groups were taking much much longer (30s+), but I'll assume that is the cluster stabilizing after the upgrade. This happens quite commonly in the field and can be seen in the logs. Next, we request all 50,000 pods on the cluster, but in chunks of 500 pods at a time. Figure : request_duration_seconds_bucket metric.
// LIST, APPLY from PATCH and CONNECT from others. 
Are you sure you want to create this branch?
How Much Are Hoa Fees In Las Vegas,
Andrew Ginther Approval Rating,
Articles P
